Publications
Publications by categories in reversed chronological order.
2025
- CoRL 2025
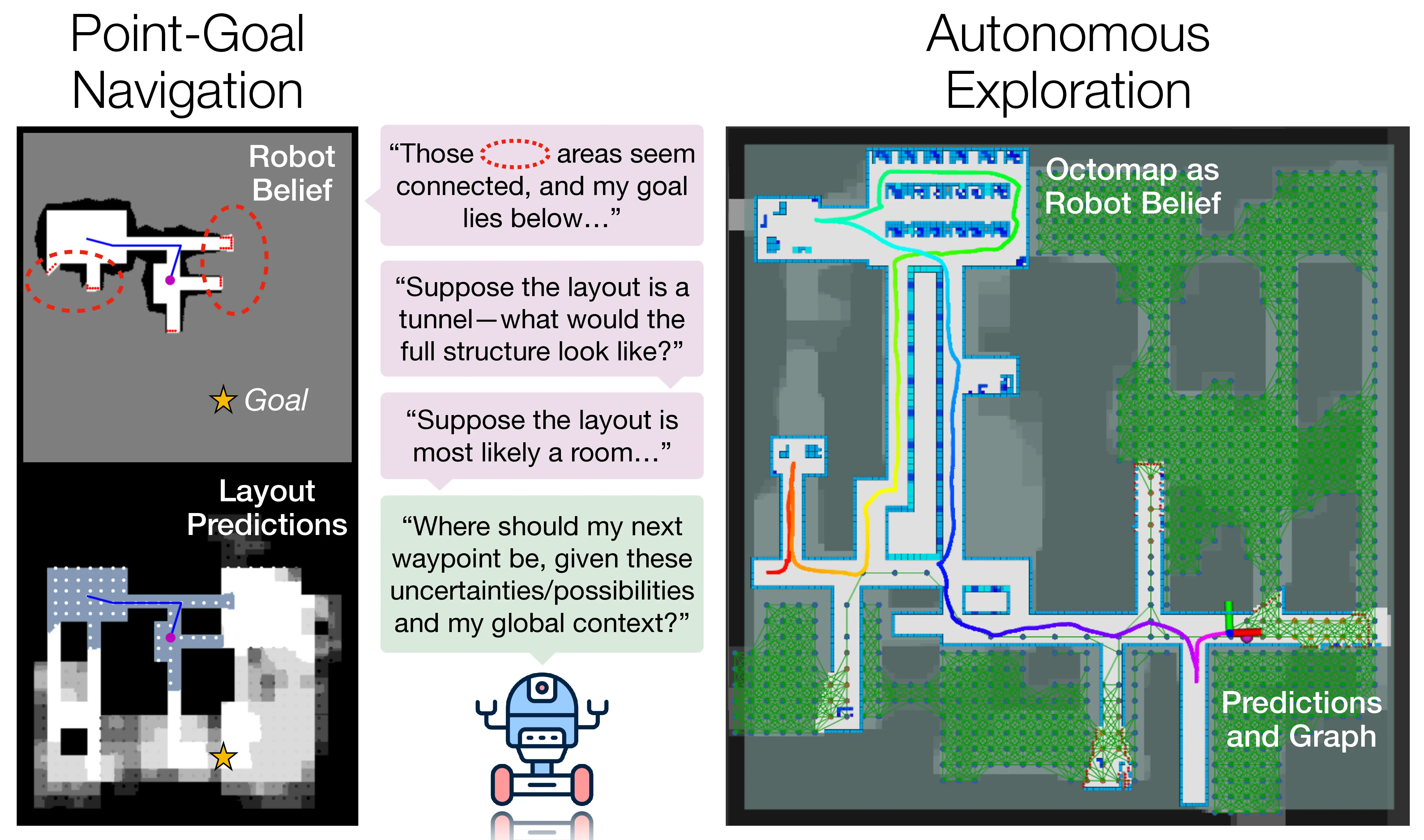 CogniPlan: Uncertainty-Guided Path Planning with Conditional Generative Layout PredictionYizhuo Wang, Haodong He, Jingsong Liang, Yuhong Cao, Ritabrata Chakraborty, and Guillaume SartorettiIn Conference on Robot Learning, 2025
CogniPlan: Uncertainty-Guided Path Planning with Conditional Generative Layout PredictionYizhuo Wang, Haodong He, Jingsong Liang, Yuhong Cao, Ritabrata Chakraborty, and Guillaume SartorettiIn Conference on Robot Learning, 2025Path planning in unknown environments is a crucial yet inherently challenging capability for mobile robots, which primarily encompasses two coupled tasks: autonomous exploration and point-goal navigation. In both cases, the robot must perceive the environment, update its belief, and accurately estimate potential information gain on-the-fly to guide planning. In this work, we propose CogniPlan, a novel path planning framework that leverages multiple plausible layouts predicted by a conditional generative inpainting model, mirroring how humans rely on cognitive maps during navigation. These predictions, based on the partially observed map and a set of layout conditioning vectors, enable our planner to reason effectively under uncertainty. We demonstrate strong synergy between generative image-based layout prediction and graph-attention-based path planning, allowing CogniPlan to combine the scalability of graph representations with the fidelity and predictiveness of occupancy maps, yielding notable performance gains in both exploration and navigation. We extensively evaluate CogniPlan on two datasets (hundreds of maps and realistic floor plans), consistently outperforming state-of-the-art planners. We further deploy it in a high-fidelity simulator and on hardware, showcasing its high-quality path planning and real-world applicability.
- ICRA 2025
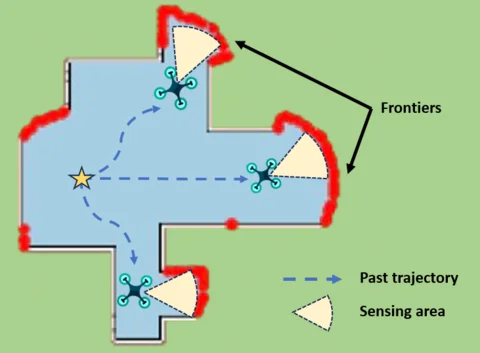 MARVEL: Multi-Agent Reinforcement Learning for constrained field-of-View multi-robot Exploration in Large-scale environmentsJimmy Chiun, Shizhe Zhang, Yizhuo Wang, Yuhong Cao, and Guillaume SartorettiIn 2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
MARVEL: Multi-Agent Reinforcement Learning for constrained field-of-View multi-robot Exploration in Large-scale environmentsJimmy Chiun, Shizhe Zhang, Yizhuo Wang, Yuhong Cao, and Guillaume SartorettiIn 2025 IEEE International Conference on Robotics and Automation (ICRA), 2025In multi-robot exploration, a team of mobile robot is tasked with efficiently mapping an unknown environments. While most exploration planners assume omnidirectional sensors like LiDAR, this is impractical for small robots such as drones, where lightweight, directional sensors like cameras may be the only option due to payload constraints. These sensors have a constrained field-of-view (FoV), which adds complexity to the exploration problem, requiring not only optimal robot positioning but also sensor orientation during movement. In this work, we propose MARVEL, a neural framework that leverages graph attention networks, together with novel frontiers and orientation features fusion technique, to develop a collaborative, decentralized policy using multi-agent reinforcement learning (MARL) for robots with constrained FoV. To handle the large action space of viewpoints planning, we further introduce a novel information-driven action pruning strategy. MARVEL improves multi-robot coordination and decision-making in challenging large-scale indoor environments, while adapting to various team sizes and sensor configurations (i.e., FoV and sensor range) without additional training. Our extensive evaluation shows that MARVEL’s learned policies exhibit effective coordinated behaviors, outperforming state-of-the-art exploration planners across multiple metrics. We experimentally demonstrate MARVEL’s generalizability in large-scale environments, of up to 90m by 90m, and validate its practical applicability through successful deployment on a team of real drone hardware.
2024
- CoRL 2024
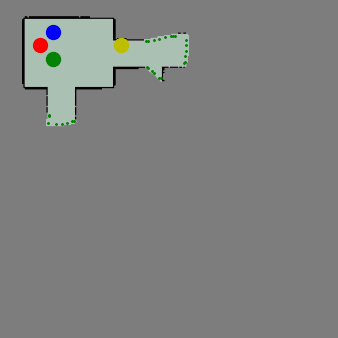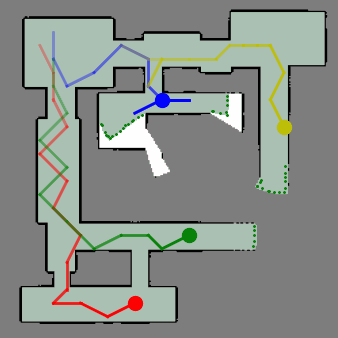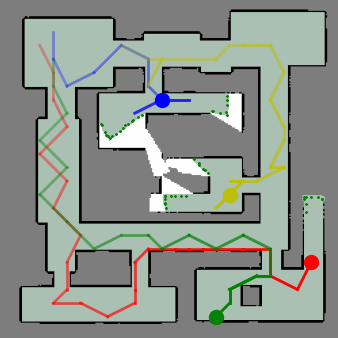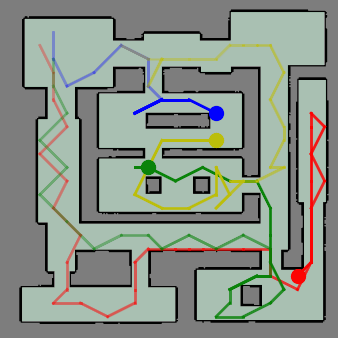 ViPER: Visibility-based Pursuit-Evasion via Reinforcement LearningYizhuo Wang, Yuhong Cao, Jimmy Chiun, Subhadeep Koley, Mandy Pham, and Guillaume SartorettiIn Conference on Robot Learning, 2024
ViPER: Visibility-based Pursuit-Evasion via Reinforcement LearningYizhuo Wang, Yuhong Cao, Jimmy Chiun, Subhadeep Koley, Mandy Pham, and Guillaume SartorettiIn Conference on Robot Learning, 2024In visibility-based pursuit-evasion tasks, a team of mobile pursuer robots with limited sensing capabilities is tasked with detecting all evaders in a multiply-connected planar environment, whose map may or may not be known to pursuers beforehand. This requires tight coordination among multiple agents to ensure that the omniscient and potentially arbitrarily fast evaders are guaranteed to be detected by the pursuers. Whereas existing methods typically rely on a relatively large team of agents to clear the environment, we propose ViPER, a neural solution that leverages a graph attention network to learn a coordinated yet distributed policy via multi-agent reinforcement learning (MARL). We experimentally demonstrate that ViPER significantly outperforms other state-of-the-art non-learning planners, showcasing its emergent coordinated behaviors and adaptability to more challenging scenarios and various team sizes, and finally deploy its learned policies on hardware in an aerial search task.
- RA-L 2024
 Deep Reinforcement Learning-based Large-scale Robot ExplorationYuhong Cao, Rui Zhao, Yizhuo Wang, Bairan Xiang, and Guillaume SartorettiIEEE Robotics and Automation Letters, 2024
Deep Reinforcement Learning-based Large-scale Robot ExplorationYuhong Cao, Rui Zhao, Yizhuo Wang, Bairan Xiang, and Guillaume SartorettiIEEE Robotics and Automation Letters, 2024In this work, we propose a deep reinforcement learning (DRL) based reactive planner to solve large-scale Lidar-based autonomous robot exploration problems in 2D action space. Our DRL-based planner allows the agent to reactively plan its exploration path by making implicit predictions about unknown areas, based on a learned estimation of the underlying transition model of the environment. To this end, our approach relies on learned attention mechanisms for their powerful ability to capture long-term dependencies at different spatial scales to reason about the robot’s entire belief over known areas. Our approach relies on ground truth information (i.e., privileged learning) to guide the environment estimation during training, as well as on a graph rarefaction algorithm, which allows models trained in small-scale environments to scale to large-scale ones. Simulation results show that our model exhibits better exploration efficiency (12% in path length, 6%in makespan) and lower planning time (60%) than the state-ofthe-art planners in a 130m x 100m benchmark scenario. We also validate our learned model on hardware.
2023
- IROS’23
 Spatio-Temporal Attention Network for Persistent Monitoring of Multiple Mobile TargetsYizhuo Wang, Yutong Wang, Yuhong Cao, and Guillaume SartorettiIn 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023
Spatio-Temporal Attention Network for Persistent Monitoring of Multiple Mobile TargetsYizhuo Wang, Yutong Wang, Yuhong Cao, and Guillaume SartorettiIn 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023This work focuses on the persistent monitoring problem, where a set of targets moving based on an unknown model must be monitored by an autonomous mobile robot with a limited sensing range. To keep each target’s position estimate as accurate as possible, the robot needs to adaptively plan its path to (re-)visit all the targets and update its belief from measurements collected along the way. In doing so, the main challenge is to strike a balance between exploitation, i.e., re-visiting previously-located targets, and exploration, i.e., finding new targets or re-acquiring lost ones. Encouraged by recent advances in deep reinforcement learning, we introduce an attention-based neural solution to the persistent monitoring problem, where the agent can learn the inter-dependencies between targets, i.e., their spatial and temporal correlations, conditioned on past measurements. This endows the agent with the ability to determine which target, time, and location to attend to across multiple scales, which we show also helps relax the usual limitations of a finite target set. We experimentally demonstrate that our method outperforms other baselines in terms of number of targets visits and average estimation error in complex environments. Finally, we implement and validate our model in a drone-based simulation experiment to monitor mobile ground targets in a high-fidelity simulator.
- J-AAMAS 2023
 Full Communication Memory Networks for Team-Level Cooperation LearningYutong Wang, Yizhuo Wang, and Guillaume SartorettiAutonomous Agents and Multi-Agent Systems, 2023
Full Communication Memory Networks for Team-Level Cooperation LearningYutong Wang, Yizhuo Wang, and Guillaume SartorettiAutonomous Agents and Multi-Agent Systems, 2023Communication in multi-agent systems is a key driver of team-level cooperation, for instance allowing individual agents to augment their knowledge about the world in partially-observable environments. In this paper, we propose two reinforcement learning-based multi-agent models, namely FCMNet and FCMTran. The two models both allow agents to simultaneously learn a differentiable communication mechanism that connects all agents as well as a common, cooperative policy conditioned upon received information. FCMNet utilizes multiple directional Long Short-Term Memory chains to sequentially transmit and encode the current observation-based messages sent by every other agent at each timestep. FCMTran further relies on the encoder of a modified transformer to simultaneously aggregate multiple self-generated messages sent by all agents at the previous timestep into a single message that is used in the current timestep. Results from evaluating our models on a challenging set of StarCraft II micromanagement tasks with shared rewards show that FCMNet and FCMTran both outperform recent communication-based methods and value decomposition methods in almost all tested StarCraft II micromanagement tasks. We further improve the performance of our models by combining them with value decomposition techniques; there, in particular, we show that FCMTran with value decomposition significantly pushes the state-of-the-art on one of the hardest benchmark tasks without any task-specific tuning. We also investigate the robustness of FCMNet under communication disturbances (i.e., binarized messages, random message loss, and random communication order) in an asymmetric collaborative pathfinding task with individual rewards, demonstrating FMCNet’s potential applicability in real-world robotic tasks.
- ICRA’23 Workshop
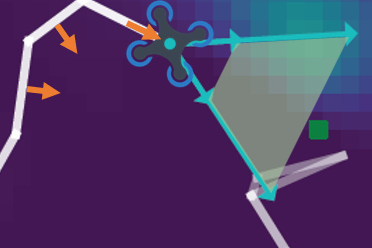 Learning Simultaneous Motion Planning and Active Gaze Control for Persistent Monitoring of Dynamic TargetsYizhuo Wang and Guillaume SartorettiIn ICRA 2023 Workshop on Active Methods in Autonomous Navigation, 2023
Learning Simultaneous Motion Planning and Active Gaze Control for Persistent Monitoring of Dynamic TargetsYizhuo Wang and Guillaume SartorettiIn ICRA 2023 Workshop on Active Methods in Autonomous Navigation, 2023We consider the persistent monitoring problem of a given set of targets moving based on an unknown model by an autonomous mobile robot equipped with a directional sensor (e.g., camera). The robot needs to actively plan both its path and its sensor’s gaze/heading direction to detect and constantly re-locate all targets by collecting measurements along its path, to keep the estimated position of each target as accurate as possible at all times. Our recent work discretize the monitoring domain into a graph where the deep-reinforcement-learning-based agent sequentially decide which neighboring node to visit next. In this work, we extend it by duplicating neighboring features multiple times and then combining with its unique gaze features to output a joint decision of “where to go" and “where to look". Our simulation experiments show that active gaze control enhances monitoring performance, particularly in terms of minimum number of re-observation per target, compared to agent with a fixed forward-gaze sensor or greedy gaze selection.
- ICRA 2023
 ARiADNE: A Reinforcement learning approach using Attention-based Deep Networks for ExplorationYuhong Cao, Tianxiang Hou, Yizhuo Wang, Xian Yi, and Guillaume SartorettiIn 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023
ARiADNE: A Reinforcement learning approach using Attention-based Deep Networks for ExplorationYuhong Cao, Tianxiang Hou, Yizhuo Wang, Xian Yi, and Guillaume SartorettiIn 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023In autonomous robot exploration tasks, a mobile robot needs to actively explore and map an unknown environment as fast as possible. Since the environment is being revealed during exploration, the robot needs to frequently re-plan its path online, as new information is acquired by onboard sensors and used to update its partial map. While state-of-the-art exploration planners are frontier- and sampling-based, encouraged by the recent development in deep reinforcement learning (DRL), we propose ARiADNE, an attention-based neural approach to obtain real-time, non-myopic path planning for autonomous exploration. ARiADNE is able to learn dependencies at multiple spatial scales between areas of the agent’s partial map, and implicitly predict potential gains associated with exploring those areas. This allows the agent to sequence movement actions that balance the natural trade-off between exploitation/refinement of the map in known areas and exploration of new areas. We experimentally demonstrate that our method outperforms both learning and non-learning state-of-the-art baselines in terms of average trajectory length to complete exploration in hundreds of simplified 2D indoor scenarios. We further validate our approach in high-fidelity Robot Operating System (ROS) simulations, where we consider a real sensor model and a realistic low-level motion controller, toward deployment on real robots.
2022
- CoRL 2022
 CAtNIPP: Context-Aware Attention-based Network for Informative Path PlanningYuhong Cao, Yizhuo Wang, Apoorva Vashisth, Haolin Fan, and Guillaume Adrien SartorettiIn Conference on Robot Learning, 2022
CAtNIPP: Context-Aware Attention-based Network for Informative Path PlanningYuhong Cao, Yizhuo Wang, Apoorva Vashisth, Haolin Fan, and Guillaume Adrien SartorettiIn Conference on Robot Learning, 2022Informative path planning (IPP) is an NP-hard problem, which aims at planning a path allowing an agent to build an accurate belief about a quantity of interest throughout a given search domain, within constraints on resource budget (e.g., path length for robots with limited battery life). IPP requires frequent online replanning as this belief is updated with every new measurement (i.e., adaptive IPP), while balancing short-term exploitation and longer-term exploration to avoid suboptimal, myopic behaviors. Encouraged by the recent developments in deep reinforcement learning, we introduce CAtNIPP, a fully reactive, neural approach to the adaptive IPP problem. CAtNIPP relies on self-attention for its powerful ability to capture dependencies in data at multiple spatial scales. Specifically, our agent learns to form a context of its belief over the entire domain, which it uses to sequence local movement decisions that optimize short- and longer-term search objectives. We experimentally demonstrate that CAtNIPP significantly outperforms state-of-the-art non-learning IPP solvers in terms of solution quality and computing time once trained, and present experimental results on hardware.